Data Mining and Warehousing Notes
All Topics (21)
- 1. What is Data Warehouse ?
- 2. Key Characteristics of a Data Warehouse
- 3. Need, Importance & Components of Data Warehousing
- 4. Data Warehouse vs OLTP
- 5. Architecture, Advantages & Applications of a Data Warehouse
- 6. Data Warehouse (DW) Delivery Process
- 7. Data Warehouse Architecture
- 8. Data Cleaning
- 9. Data Integration
- 10. Data Transformation
- 11. Data Reduction
- 12. Data Warehouse Schema Design
- 13. Partitioning Strategy in Data Warehouse Implementation
- 14. Data Marts
- 15. Metadata
- 16. Example of a Multidimensional Data Model
- 17. Pattern Warehousing
- 18. OLAP Systems
- 19. OLAP Queries
- 20. OLAP Servers
- 21. OLAP Operations
6. Data Warehouse (DW) Delivery Process
A Data Warehouse Delivery Process is the end-to-end lifecycle of delivering a working, reliable DW solution—from requirements gathering to maintenance.
It consists of 6 major stages:
1. Requirements Gathering & Business Analysis
Purpose: Understand business needs for data and analytics.
Activities:
-
Identify business processes: Sales, Finance, Inventory, CRM, etc.
-
Determine analytical requirements: KPIs, metrics, reports, dashboards, data granularity (daily, hourly, transactional).
-
Conduct stakeholder interviews.
-
Gather functional & non-functional requirements (performance, SLAs, security).
Outputs:
a) Business Requirement Document (BRD)
b) Use cases, dashboard/report mockups
c) List of data sources
2. Data Warehouse Architecture & Design
Purpose: Define how the DW will be structured.
2.1 High-Level Architecture
-
Choose DW architecture:
-
Kimball (Dimensional – Star Schema)
-
Inmon (Normalized – Enterprise DW)
-
Data Vault
-
Modern Cloud DW (Snowflake, BigQuery, Redshift)
-
2.2 Data Modeling
-
Identify facts and dimensions
-
Define grain (level of detail)
-
Design schemas: Star/Snowflake, conformed dimensions
-
Plan surrogate keys and Slowly Changing Dimensions (SCD types 1, 2, 3)
2.3 Technical Design
-
ETL/ELT architecture
-
Data staging design
-
Metadata repository
-
Error handling, logging
-
Security & access control
-
Data quality rules
Outputs:
a) Logical & physical data models
b) Architecture diagrams
c) ETL specification documents
3. ETL / ELT Development
ETL is the backbone of DW delivery.
3.1 Extraction
-
Connect to sources: Databases, files, APIs, SaaS, streams
-
Extract full or incremental data
-
Handle CDC (Change Data Capture), timestamps, and logs
3.2 Transformation
-
Data cleansing (nulls, invalid values)
-
Standardization (dates, units)
-
Apply business rules
-
Deduplication
-
Derive metrics and surrogate keys
-
Handle SCD for dimensions
3.3 Loading
-
Load data: Stage → Integration → Dimensional layer
-
Load facts & dimensions
-
Log errors/exceptions
-
Optimize performance (bulk loads, partitioning)
Outputs:
a) ETL/ELT pipelines
b) Staging & transformed datasets
c) Data validation scripts
4. Testing & Quality Assurance
Ensures accuracy, completeness, and performance.
Types of Testing:
-
Unit Testing: Individual ETL modules
-
System/Integration Testing: Full pipeline flow
-
Data Quality Testing: Nulls, duplicates, integrity constraints, referential integrity
-
Performance Testing: Query optimization, batch load performance
-
User Acceptance Testing (UAT): Business validation of reports/KPIs
Outputs:
a) Test cases & results
b) Sign-off from business users
5. Deployment & Production Rollout
Activities:
-
Infrastructure setup (on-premises or cloud)
-
Automate workflows using schedulers (Airflow, Cron, Data Factory)
-
Deploy ETL pipelines
-
Initial historical load
-
Configure access & permissions
-
Set up monitoring dashboards
Outputs:
a) Production-ready data warehouse
b) Automated nightly/real-time pipelines
c) Security & governance policies
6. Maintenance, Monitoring & Enhancements
Activities:
-
Monitor pipeline health and performance
-
Handle incremental loads
-
Resolve data quality issues
-
Manage schema changes
-
Add new data sources or KPIs
-
Continuous optimization
Monitoring Tools:
-
Airflow / Luigi
-
CloudWatch / Stackdriver
-
Grafana
-
ETL tool dashboards
Outputs:
a) Stable, scalable DW
b) Continuous improvements
Delivery Process Flow
↓
2. Architecture & Data Modeling
↓
3. ETL/ELT Development
↓
4. Testing (Unit → UAT)
↓
5. Deployment to Production
↓
6. Maintenance & Enhancements
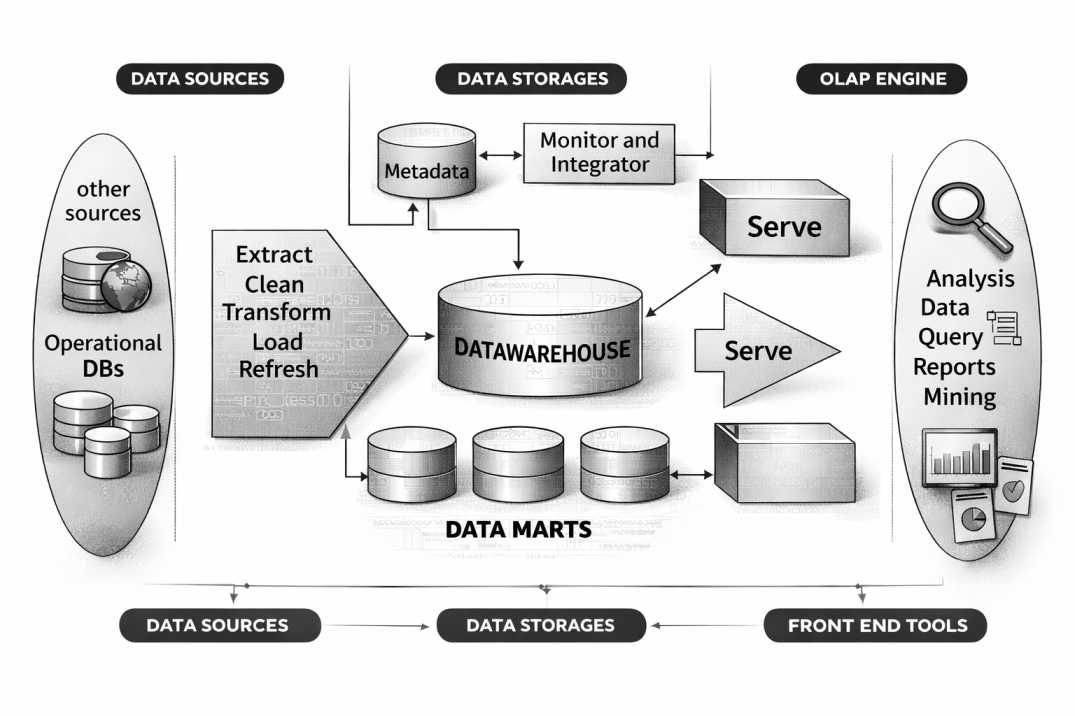
7. Data Warehouse Architecture
A Data Warehouse Architecture defines how data is collected, stored, managed, and delivered for analysis and reporting.
Key Characteristics
- Subject-oriented → Organized by business subjects (sales, finance)
- Integrated → Combines data from multiple sources
- Time-variant → Stores historical data
- Non-volatile → Data is stable (not frequently changed)
1. Data Sources (Operational Systems)
These are the original systems from where data is collected.
Types
- OLTP systems (ERP, CRM, Billing)
- External data (market data, APIs, flat files)
- Logs & semi-structured data
Role
- Provide raw transactional data
2. ETL / ELT Layer (Data Integration Layer)
ETL (Extract – Transform – Load)
- Data is transformed before loading into warehouse
ELT (Extract – Load – Transform)
- Data is loaded first, then transformed inside warehouse
- Common in cloud systems
Key Functions
- Data cleaning
- Data validation
- Data transformation
- Data integration (multiple sources)
- Data loading (batch / real-time)
3. Staging Area
A temporary storage area used during ETL.
Features
- Stores raw extracted data
- Used for cleansing, sorting, transformation
- Not accessible to end users
Purpose
- Prevents overloading of source systems
4. Data Storage Layer (Data Warehouse Repository)
a. Enterprise Data Warehouse (EDW)
- Centralized warehouse
- Provides single version of truth
b. Data Marts
- Subsets of warehouse
- Department-specific (Sales, Finance)
Types:
- Dependent → From EDW
- Independent → Directly from sources
Storage Approaches
- Relational databases (SQL)
- Cloud warehouses (Snowflake, BigQuery, Redshift)
- Distributed systems (Hadoop, Hive)
5. Metadata Layer
Metadata = “Data about data”
Types
- Technical metadata → tables, columns, data types
- Business metadata → rules, KPIs, definitions
- Operational metadata → ETL logs, load timings
Purpose
- Helps users understand and trust data
6. OLAP Engine (Query Processing Layer)
Used for fast analytical processing.
Types of OLAP
- ROLAP → Relational databases
- MOLAP → Multidimensional cubes
- HOLAP → Hybrid approach
Features
- Slice & Dice
- Drill-down / Roll-up
- Pivoting
- Aggregation
7. Presentation Layer (BI / Reporting Tools)
Provides access to end-users.
Tools
- Power BI
- Tableau
- Qlik
- Excel
Purpose
- Data visualization
- Reporting
- Analytics
- Business insights
8. Data Cleaning
Data Cleaning is the process of detecting, correcting, or removing corrupt, inaccurate, incomplete, inconsistent, and irrelevant data from a dataset.
It is essential because real-world data is messy, and poor-quality data leads to poor-quality models.
1. Handling Missing Data
Missing values can occur due to human error, system issues, or incomplete records.
Techniques:
a. Deletion Methods
- Listwise Deletion (Remove Entire Record)
- If a row has missing values, delete the entire row.
- Useful when: Few records are missing, and data size is large.
- Pairwise Deletion
- Use available values for each analysis without deleting whole rows.
b. Imputation Methods
- Mean/Median/Mode Imputation → Replace missing values using basic statistics.
- K-Nearest Neighbors (KNN) Imputation → Uses similar rows to estimate missing values.
- Regression Imputation → Predict missing values using regression models.
- Multiple Imputation → Advanced statistical technique for unbiased estimates.
2. Handling Noisy Data
Noise = random error or variance in data.
Techniques:
- Smoothing
- Moving averages
- Binning (equal width, equal frequency)
- Regression smoothing
- Outlier Detection & Removal
- Z-score method
- IQR method (Q1 − 1.5IQR, Q3 + 1.5IQR)
- DBSCAN clustering
- Transformation
- Log transform
- Power transform
3. Handling Inconsistent Data
Inconsistencies occur due to different naming conventions or data entry errors.
Examples:
- “Male”, “M”, “m”, “MALE”
- "USA", "United States", "U.S."
Techniques:
- Standardization Rules → Define uniform formats for text, dates, categories.
- Data Validation Rules → Example: age should be 0–120.
- Referential Integrity Checks → Ensure foreign keys match primary keys.
4. Handling Duplicate Data
Duplicate records arise from merging datasets or repeated entries.
Techniques:
- Exact match detection (same values across rows)
- Fuzzy matching (similar but not identical values)
- Record linkage (identify same entity across sources)
- Remove / merge duplicates
5. Handling Incorrect or Invalid Data
Incorrect data includes typos, wrong values, or impossible values.
Techniques:
- Validation Checks
- Range checks (e.g., salary ≥ 0)
- Type checks (integers, strings)
- Format checks (email, phone number)
- Dictionary / Master Data Lookup → To correct category mistakes (e.g., "India" → “India”)
- Business Rules → Example: transaction date cannot be in the future
6. Handling Irrelevant Data
Irrelevant features do not contribute to analysis or modeling.
Techniques:
- Feature Selection
- Filter methods (correlation, chi-square)
- Wrapper methods (RFE)
- Embedded methods (Lasso)
- Domain Knowledge Filtering → Remove attributes not needed for analysis
7. Data Integration Issues (Part of Cleaning)
When combining multiple sources, errors may occur.
Problems:
- Naming conflicts
- Unit inconsistencies (kg vs lbs)
- Schema mismatch (different column layouts)
- Duplicate records across sources
Solutions:
- Schema integration
- Entity resolution
- Standardization of measurement units
9. Data Integration
Data Integration is the process of combining data from multiple heterogeneous sources into a unified, consistent view.
Sources may include:
- Databases (SQL/NoSQL)
- Flat files (CSV, Excel)
- ERP / CRM systems
- Web data / Logs
- Cloud storage
Goal: Create a single, consistent dataset for analysis or storage in a data warehouse.
Key Issues in Data Integration
1.1 Schema Integration
- Different sources may use different structures.
Example: - Source A: Cust_ID, FName, LName
- Source B: CustomerNo, FirstName, LastName
Solution:
- Match attributes using schema mapping / metadata
1.2 Data Value Conflicts
- Same data represented differently.
Examples: - “Male” vs “M”
- “USA” vs “United States”
- Date formats: DD/MM/YYYY vs MM/DD/YYYY
- Units: kg vs lbs
Solution:
- Create standardized formats or conversion rules
1.3 Entity Identification Problem
- Determining if records from different sources refer to the same real-world entity.
Example:
- John Doe, 123-45-6789
- J. Doe, SSN: 123456789
Solution:
- Matching keys (primary / foreign keys)
- Fuzzy matching / record linkage
- Master Data Management (MDM)
1.4 Redundancy and Duplicate Detection
- Combining data may introduce duplicates.
Solution:
- Remove duplicates
- Merge records
- Use deduplication tools / matching algorithms
1.5 Data Granularity Issues
- Different levels of detail in different sources.
Example:
- Sales per day in one source
- Sales per month in another
Solution:
- Aggregation or disaggregation during integration
Techniques Used in Data Integration
- ETL (Extract, Transform, Load)
- Data federation / Virtual integration
- Data warehousing
- Data Lake integration
- Enterprise Information Integration (EII)
- Schema matching and mapping
2. Data Transformation
Data Transformation modifies, consolidates, or restructures data into a suitable format for analysis or mining.
- Usually comes after data integration in pipelines.
2.1 Smoothing
- Reduces noise in data.
Techniques: - Moving average
- Binning
- Regression smoothing
2.2 Aggregation
- Combines data to produce summary information.
Examples:
- Summing monthly sales → yearly sales
- Converting hourly data → daily averages
Used in:
- Data warehousing (fact tables)
- OLAP cube creation
2.3 Generalization
- Replacing low-level data with higher-level concepts.
Examples:
- City → State → Country
- Age → Age group (0–10, 11–20, etc.)
Used in:
- Data cubes
- Concept hierarchies
2.4 Normalization (Feature Scaling)
- Brings numerical values to a common scale for ML.
Techniques:
-
Min-Max Normalization:
x′ = x − min
Z-score Standardization:
- Decimal Scaling
x′ = x − μ / σ
2.5 Attribute / Feature Construction
- Creating new attributes from existing ones.
Examples:
- BMI = weight / height²
- FullName = FirstName + LastName
- Revenue = Price × Quantity
Benefit: Improves data quality & model performance
2.6 Discretization
- Converting continuous data → discrete bins
Example:
- Age → {Child, Adult, Senior}
Techniques:
- Binning
- Histogram-based
- Decision-tree-based
2.7 Encoding Categorical Data
- Prepares categorical data for ML models
Techniques:
- Label Encoding
- One-hot Encoding
- Target Encoding
2.8 Data Reduction (Part of Transformation)
- Reduces data size while maintaining integrity
Techniques:
- PCA (Principal Component Analysis)
- Sampling
- Data cube aggregation
- Attribute subset selection
10. Data Transformation
Data Transformation is the process of converting data into a proper, meaningful, and useful format for analysis or data mining.
It is performed after Data Cleaning and Data Integration.
1. Smoothing (Noise Removal)
Used to remove random errors or fluctuations (noise) from data.
Techniques:
- Binning
- Equal-width binning
- Equal-frequency binning
- Moving Average
- Regression Smoothing
2. Aggregation
Combining data to create summarized information.
Examples:
- Daily data → Monthly data
- Monthly sales → Yearly sales
- Operations: Sum, Average, Count
Uses:
- OLAP
- Data Cubes
- Data Warehouses
3. Generalization
Replacing low-level (detailed) data with higher-level concepts.
Examples:
- City → State → Country
- Age → Age Group (0–10, 11–20, 21–30)
Uses:
- Concept Hierarchies
- Data Cubes
4. Normalization (Feature Scaling)
Scaling data values to a common range for better performance of ML models.
Types:
(a) Min–Max Normalization:
(b) Z-score Standardization:
5. Attribute Construction (Feature Construction)
Creating new attributes from existing data.
Examples:
- BMI = Weight / Height²
- Full Name = First Name + Last Name
- Revenue = Price × Quantity
Advantage: Improves model performance.
6. Discretization
Converting continuous data into discrete categories (bins).
Example:
- Age → {Child, Adult, Senior}
Techniques:
- Binning
- Histogram Method
- Decision Tree-Based Discretization
7. Categorical Data Transformation
Converting categorical (text) data into numeric form for ML models.
Techniques:
- Label Encoding
- One-Hot Encoding
- Binary Encoding
- Target Encoding
8. Data Reduction (Optional in Transformation)
Reducing data size while preserving important information.
Techniques:
- PCA (Principal Component Analysis)
- Sampling
- Attribute Subset Selection
- Data Cube Aggregation