Topics
- 1. What is Big Data?
- 2. Big Data Characteristics
- 3. Types of Big Data
Big Data refers to extremely large and complex datasets that cannot be efficiently stored, processed, or analyzed using traditional data processing tools such as relational databases.
These datasets are generated continuously from multiple sources such as social media platforms, sensors, online transactions, videos, images, and digital devices. Because of the massive size and complexity of this data, special technologies are required to store and analyze it.
Examples of Big Data
-
Social media posts and comments
-
Online shopping transactions
-
YouTube videos and multimedia content
-
Sensor and IoT device data
-
Satellite images
-
Server and website logs
2. Characteristics of Big Data (5 V's)
Big Data is commonly described using five important characteristics known as the 5 V’s.
2.1 Volume
Volume refers to the huge amount of data generated every day from various sources.
Example:
-
Billions of photos and posts uploaded daily on social media platforms.
2.2 Velocity
Velocity refers to the speed at which data is generated, collected, and processed.
Example:
-
Real-time stock market updates
-
GPS location tracking
-
Online transactions
2.3 Variety
Variety refers to the different types of data formats that are generated.
Types of Data:
Structured Data
-
Organized in tables with rows and columns
-
Example: Databases, spreadsheets
Semi-Structured Data
-
Partially organized data
-
Example: XML, JSON files
Unstructured Data
-
Data without a fixed structure
-
Example: Images, videos, audio files, text
2.4 Veracity
Veracity refers to the accuracy, reliability, and quality of data.
Sometimes data may contain errors, missing values, or noise. If the data quality is poor, it may lead to incorrect analysis and wrong decisions.
2.5 Value
Value refers to the useful insights and benefits obtained from data analysis.
Organizations analyze big data to understand customer behavior, improve services, and increase profits.
Example:
-
Online shopping websites recommend products based on user behavior.
3. Sources of Big Data
Big Data is generated from many different sources.
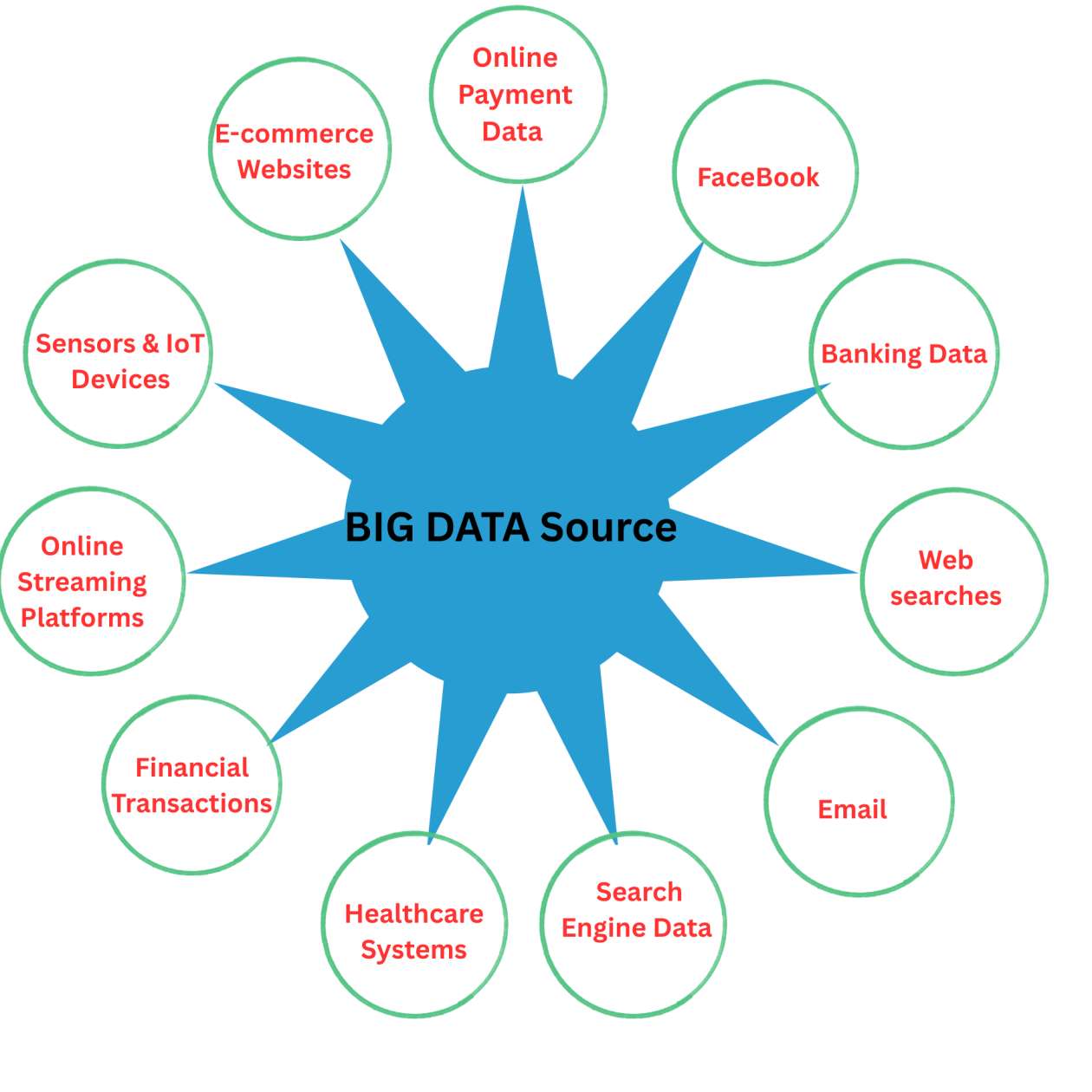
3.1 Social Media
Social media platforms generate huge amounts of data every second.
Examples:
-
Facebook
-
Instagram
-
Twitter
-
YouTube
Types of data:
-
Likes
-
Comments
-
Shares
-
Videos
3.2 Machine and IoT Data
Machines and smart devices collect data using sensors.
Examples:
-
Smart home devices
-
GPS trackers
-
Industrial machines
-
Wearable devices
3.3 Transactional Data
Transactional data is generated during online and offline business transactions.
Examples:
-
E-commerce purchases
-
Online payments
-
Banking transactions
3.4 Government and Scientific Data
Government agencies and research organizations produce large datasets.
Examples:
-
Healthcare records
-
Weather data
-
Scientific research data
3.5 Web and Server Logs
Websites and applications record user activities.
Examples:
-
Website clickstream data
-
Application usage logs
-
Server logs
4. Importance of Big Data
Big Data plays an important role in modern industries and organizations.
Benefits of Big Data
-
Better decision making
-
Understanding customer behavior
-
Fraud detection
-
Improving business efficiency
-
Identifying trends and patterns
-
Developing new products and services
Example
E-commerce companies analyze customer searches and purchase history to recommend personalized products.
5. Big Data Technologies
Traditional systems cannot handle Big Data efficiently, so specialized technologies are used.
5.1 Hadoop Ecosystem
Hadoop is an open-source framework used for storing and processing large datasets across distributed systems.
Main components of Hadoop:
HDFS (Hadoop Distributed File System)
-
Used for distributed storage of big data.
MapReduce
-
A programming model used for processing large datasets.
YARN (Yet Another Resource Negotiator)
-
Manages cluster resources and job scheduling.
Other tools in Hadoop ecosystem:
-
Hive
-
Pig
5.2 Apache Spark
Apache Spark is a fast big data processing engine.
Features:
-
Faster than MapReduce
-
Supports real-time data processing
-
Used in machine learning and streaming applications
5.3 NoSQL Databases
NoSQL databases are designed to store and manage large volumes of unstructured or semi-structured data.
Examples:
-
MongoDB
-
Cassandra
-
CouchDB
5.4 Cloud Platforms
Cloud computing makes it easier to store and process Big Data.
Examples of cloud platforms:
-
Amazon Web Services (AWS)
-
Microsoft Azure
-
Google Cloud Platform (GCP)
6. Applications of Big Data
Big Data is widely used in many fields.
6.1 Healthcare
-
Disease prediction
-
Patient data analysis
-
Medical research
6.2 Business and Marketing
-
Customer segmentation
-
Targeted advertising
-
Sales prediction
6.3 Banking and Finance
-
Fraud detection
-
Risk analysis
-
Credit scoring
6.4 Transportation
-
Traffic management
-
Route optimization used by ride-sharing services
6.5 Social Media Platforms
-
Trend analysis
-
Sentiment analysis (understanding user opinions and emotions)
7. Future of Big Data
Big Data is becoming the backbone of modern technologies. With the growth of Artificial Intelligence, Machine Learning, Cloud Computing, and IoT, the importance of Big Data will continue to increase.
Future applications include:
-
Smart cities
-
Automated systems
-
Advanced healthcare analytics
-
Personalized digital services
Big Data is commonly described through specific characteristics that define its nature and complexity.
Initially, Big Data was explained using 3 V’s (Volume, Velocity, Variety). Later, researchers added more characteristics to better describe Big Data.
Today, Big Data is usually explained using 5 V’s or sometimes 7 V’s.
1. Volume (Amount of Data)
Meaning
Volume refers to the huge amount of data generated every second from various sources.
Examples
-
Social media platforms generate petabytes of data daily.
-
Users upload hundreds of hours of videos every minute on video platforms.
-
Online shopping websites store millions of customer transactions.
Why It Matters
Traditional databases cannot store or manage such massive datasets efficiently. Therefore, Big Data technologies like distributed storage systems and cloud platforms are used.
2. Velocity (Speed of Data Generation)
Meaning
Velocity refers to the speed at which data is generated, collected, and processed.
Examples
-
Stock market data updates within milliseconds.
-
GPS tracking systems update location data continuously.
-
Social media platforms generate likes, comments, and posts rapidly.
Why It Matters
High-speed data requires real-time processing systems to analyze information quickly and make instant decisions.
3. Variety (Different Types of Data)
Meaning
Variety refers to the different formats and types of data generated from multiple sources.
Types of Data
1. Structured Data
-
Organized in rows and columns
-
Stored in relational databases
-
Example: Database tables, spreadsheets
2. Semi-Structured Data
-
Partially organized data
-
Contains tags or markers
-
Example: XML, JSON, HTML
3. Unstructured Data
-
Data without a predefined format
-
Example: Images, videos, audio files, emails, social media posts
Why It Matters
Managing different types of data requires flexible storage systems such as NoSQL databases.
4. Veracity (Trustworthiness of Data)
Meaning
Veracity refers to the accuracy, reliability, and quality of data.
Challenges
-
Incomplete data
-
Duplicate data
-
Incorrect or noisy data
Examples
-
Fake social media profiles generating misleading data
-
Incorrect sensor readings
Why It Matters
Poor-quality data can lead to wrong analysis and incorrect business decisions. Therefore, data cleaning and validation processes are necessary.
5. Value (Importance of Data)
Meaning
Value refers to the useful insights and benefits derived from analyzing Big Data.
Examples
-
Predicting customer behavior
-
Improving business strategies
-
Detecting fraud in banking systems
-
Optimizing transportation routes
Why It Matters
Even if data is large, fast, and diverse, it is useless unless it provides meaningful insights and business value.
Additional Characteristics (7V Model)
Some modern Big Data frameworks include two additional characteristics, expanding the model to 7 V’s.
6. Variability
Meaning
Variability refers to the inconsistency and fluctuations in data flow.
Examples
-
Social media trends changing rapidly
-
Seasonal increases in online shopping
-
Weather data showing unpredictable patterns
Why It Matters
Systems must be able to handle changing data patterns and sudden spikes in data volume.
7. Visualization
Meaning
Visualization refers to the presentation of Big Data in graphical formats so that it can be easily understood.
Examples of Visualization Tools
-
Dashboards
-
Graphs and charts
-
Data reports
Common Tools Used
-
Tableau
-
Power BI
-
QlikView
Why It Matters
Visualization helps analysts and decision-makers interpret complex data quickly and effectively.
Summary of Big Data Characteristics
| Characteristic | Meaning | Example |
|---|---|---|
| Volume | Large amount of data | Social media data, video uploads |
| Velocity | Speed of data generation | Stock market updates, GPS tracking |
| Variety | Different data types | Text, images, videos |
| Veracity | Accuracy and reliability | Authentic vs fake data |
| Value | Useful insights from data | Customer behavior analysis |
| Variability | Inconsistent data flow | Social media trends |
| Visualization | Data shown in visual form | Dashboards and charts |
Big Data is broadly classified into three main types:
-
Structured Data
-
Unstructured Data
-
Semi-Structured Data
Additionally, Big Data can also be categorized based on its source.
1. Structured Data
Definition
Structured data is organized and arranged in a fixed format (rows, columns, tables).
It can be easily stored, processed, and analyzed using traditional databases (SQL).
Characteristics
-
Highly organized and well-defined
-
Easy to search, retrieve, and analyze
-
Follows a definite schema
-
Stored in relational databases
Examples
-
Bank transaction records
-
Employee details (name, salary, ID)
-
Student records in tables
-
Sales records (Excel sheets)
-
ATM transaction logs
Tools Used
-
SQL databases: MySQL, Oracle, PostgreSQL
-
Data warehouses
2. Unstructured Data
Definition
Unstructured data does not have a predefined format or structure.
It is complex and requires advanced tools to store and process.
Characteristics
-
Very complex and difficult to analyze
-
Does not follow any schema
-
Cannot be stored directly in relational databases
Examples
-
Images, videos, audio files
-
Social media posts (tweets, comments, reels)
-
Emails
-
PDFs, documents
-
Website content
-
CCTV footage
Tools Used
-
Hadoop (HDFS)
-
Apache Spark
-
NoSQL databases (MongoDB, Cassandra)
3. Semi-Structured Data
Definition
Semi-structured data does not follow a rigid table structure, but contains some organizational properties like tags or markers.
It lies between structured and unstructured data.
Characteristics
-
Flexible structure
-
Contains metadata
-
Easier to analyze than unstructured data
-
Does not require a fixed schema
Examples
-
JSON files
-
XML files
-
HTML pages
-
Emails (headers structured, body unstructured)
-
Log files
-
Sensor data with tags
Tools Used
-
NoSQL databases
-
Big Data frameworks
-
Document stores (MongoDB)
4. Summary Table – Types of Big Data
| Type of Data | Structure | Examples | Storage / Tools |
|---|---|---|---|
| Structured | Organized in tables | Banking records, Excel sheets | SQL Databases |
| Unstructured | No fixed format | Videos, images, social media posts | Hadoop, Spark, NoSQL |
| Semi-Structured | Partially organized | JSON, XML, log files | NoSQL, MongoDB |